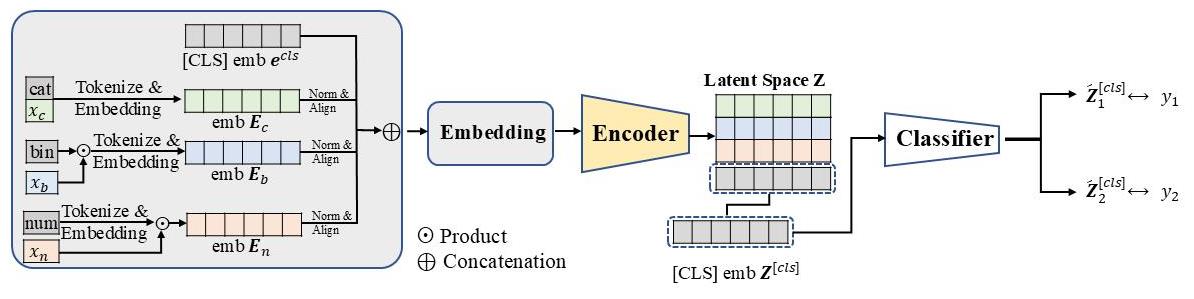
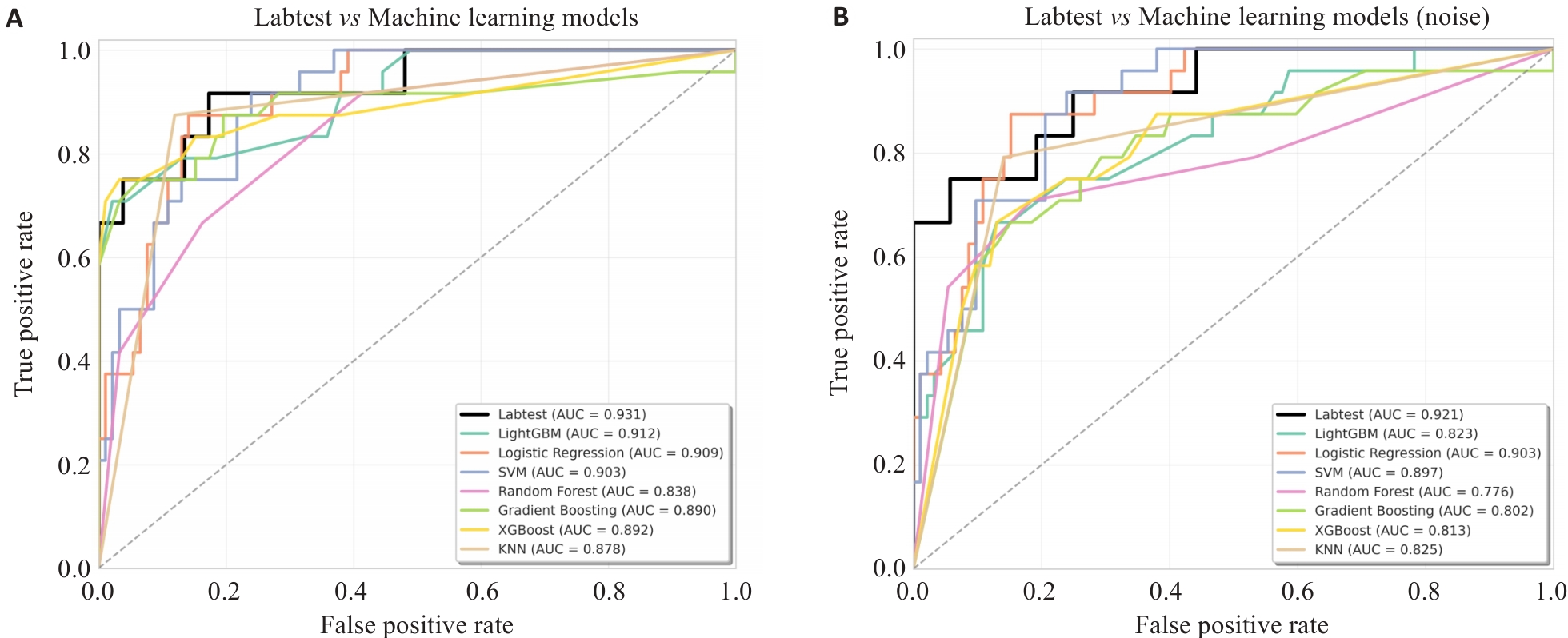
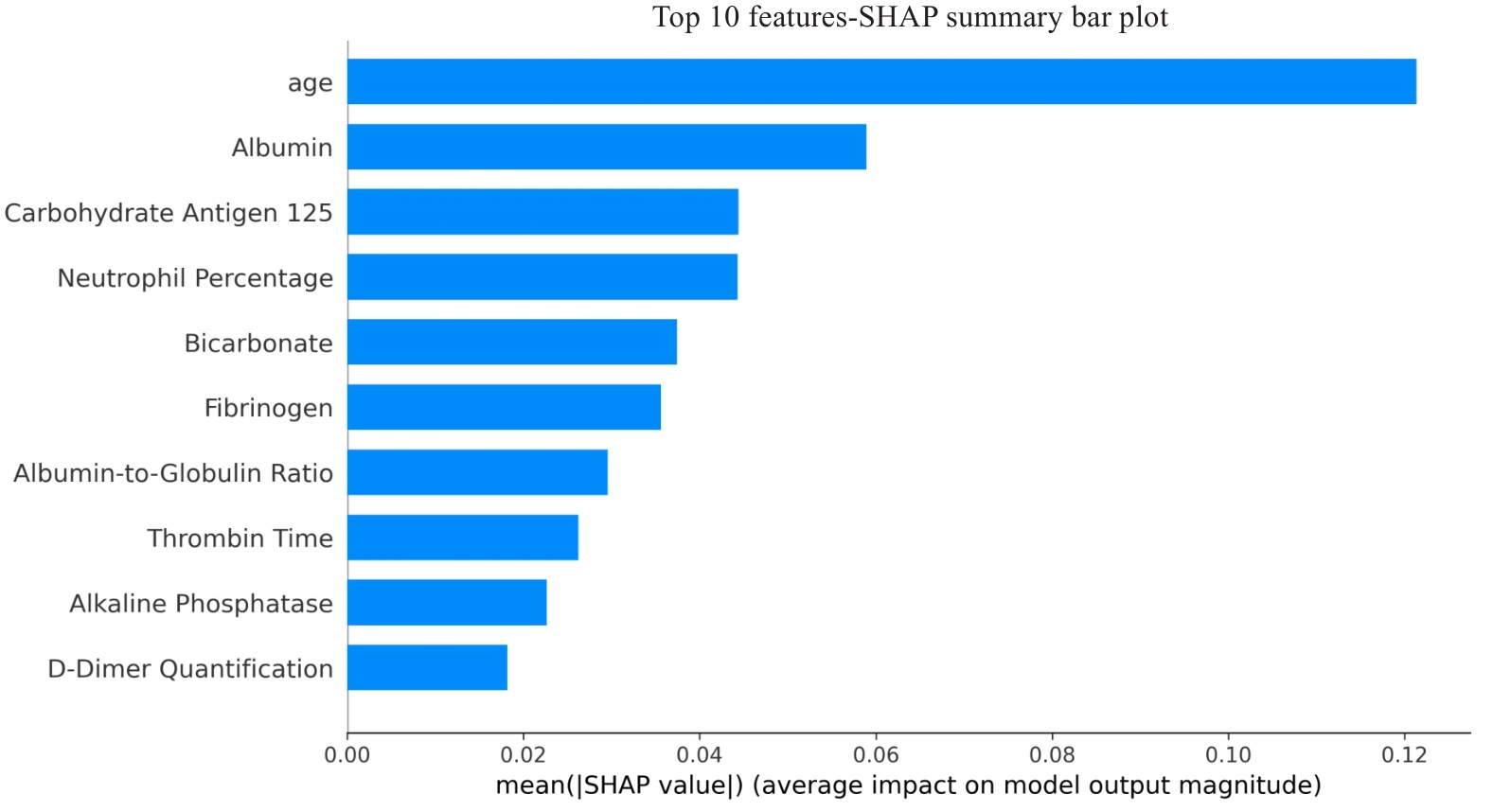
| [1] |
Han BF, Zheng RS, Zeng HM, et al. Cancer incidence and mortality in China, 2022[J]. J Natl Cancer Cent, 2024, 4(1): 47-53. doi:10.1016/j.jncc.2024.01.006
|
| [2] |
Zeng HM, Zheng RS, Guo YM, et al. Cancer survival in China, 2003-2005: a population-based study[J]. Int J Cancer, 2015, 136(8): 1921-30. doi:10.1002/ijc.29227
|
| [3] |
Dochez V, Caillon H, Vaucel E, et al. Biomarkers and algorithms for diagnosis of ovarian cancer: CA125, HE4, RMI and ROMA, a review[J]. J Ovarian Res, 2019, 12(1): 28. doi:10.1186/s13048-019-0503-7
|
| [4] |
Guo YY, Jiang TJ, Ouyang LL, et al. A novel diagnostic nomogram based on serological and ultrasound findings for preoperative prediction of malignancy in patients with ovarian masses[J]. Gynecol Oncol, 2021, 160(3): 704-12. doi:10.1016/j.ygyno.2020.12.006
|
| [5] |
Madan S, Lentzen M, Brandt J, et al. Transformer models in biomedicine[J]. BMC Med Inform Decis Mak, 2024, 24(1): 214. doi:10.1186/s12911-024-02600-5
|
| [6] |
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Adv Neural Inf Process Syst, 2017, 30: 6000-10.
|
| [7] |
Gorishniy Y, Rubachev I, Babenko A. On embeddings for numerical features in tabular deep learning[J]. Adv Neural Inf Process Syst, 2022, 35: 24991-5004. doi:10.52202/068431-1812
|
| [8] |
Somepalli G, Goldblum M, Schwarzschild A, et al. SAINT: improved neural networks for tabular data via row attention and contrastive pre-training[J]. arXiv preprint arXiv: 2106. 01342, 2021.
|
| [9] |
Wang Z, Sun J. Transtab: learning transferable tabular transformers across tables[J]. Adv Neural Inf Process Syst, 2022, 35: 2902-15. doi:10.52202/068431-0210
|
| [10] |
Guyon I, Elisseeff A. An introduction to variable and feature selection[J]. J Mach Learn Res, 2003, 3: 1157-82.
|
| [11] |
Azur MJ, Stuart EA, Frangakis C, et al. Multiple imputation by chained equations: what is it and how does it work[J]. Int J Methods Psych Res, 2011, 20(1): 40-9. doi:10.1002/mpr.329
|
| [12] |
Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift[J]. Proc Mach Learn Res, 2015, 37: 448-56.
|
| [13] |
Lin BY, Lee S, Khanna R, et al. Birds have four legs? NumerSense: probing numerical commonsense knowledge of pre-trained language models[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Online. Stroudsburg, PA, USA: ACL, 2020. DOI:10.18653/v1/2020.emnlp-main.557 .
|
| [14] |
Ba JL, Kiros JR, Hinton GE. Layer normalization[J]. arXiv preprint arXiv:, 2016. doi:10.48550/arXiv.1607.06450
|
| [15] |
Chai YK, Jin S, Hou XW. Highway transformer: self-gating enhanced self-attentive networks[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online. Stroudsburg, PA, USA: ACL, 2020. DOI:10.18653/v1/2020.acl-main.616 .
|
| [16] |
Lin TY, Wang YX, Liu XY, et al. A survey of transformers[J]. AI Open, 2022, 3: 111-32. doi:10.1016/j.aiopen.2022.10.001
|
| [17] |
Devlin J, Chang MW, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C] //Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2019. doi:10.18653/v1/n19-1423
|
| [18] |
Zhou ZW, Rahman Siddiquee MM, Tajbakhsh N, et al. UNet++: a nested U-Net architecture for medical image segmentation[C]//Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support. Cham: Springer, 2018: 3-11. doi:10.1007/978-3-030-00889-5_1
|
| [19] |
Campbell TW, Wilson MP, Roder H, et al. Predicting prognosis in COVID-19 patients using machine learning and readily available clinical data[J]. Int J Med Inform, 2021, 155: 104594. doi:10.1016/j.ijmedinf.2021.104594
|
| [20] |
Ke G, Meng Q, Finley T, et al. LightGBM: a highly efficient gradient boosting decision tree[C] // Advances in Neural Information Processing Systems, 2017:30.
|
| [21] |
Cox DR. The regression analysis of binary sequences[J]. J R Stat Soc Ser B Stat Methodol, 1958, 20(2): 215-32. doi:10.1111/j.2517-6161.1958.tb00292.x
|
| [22] |
Cortes C, Vapnik V. Support-vector networks[J]. Mach Learn, 1995, 20(3): 273-97. doi:10.1007/bf00994018
|
| [23] |
Breiman L. Random forests[J]. Mach Learn, 2001, 45(1): 5-32. doi:10.1023/a:1010933404324
|
| [24] |
Friedman JH. Greedy function approximation: a gradient boosting machine[J]. Ann Statist, 2001, 29(5): 1189-232. doi:10.1214/aos/1013203451
|
| [25] |
Chen TQ, Guestrin C. XGBoost: a scalable tree boosting system[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco California USA. ACM, 2016: 785-94. DOI:10.1145/2939672.2939785 .
|
| [26] |
Cover T, Hart P. Nearest neighbor pattern classification[J]. IEEE Trans Inform Theory, 1967, 13(1): 21-7. doi:10.1109/tit.1967.1053964
|
| [27] |
Lundberg SM, Lee SI. A unified approach to interpreting model predictions[J]. Adv Neural Inf Process Syst, 2017, 30: 4768-77.
|
| [28] |
Charkhchi P, Cybulski C, Gronwald J, et al. CA125 and ovarian cancer: a comprehensive review[J]. Cancers, 2020, 12(12): 3730. doi:10.3390/cancers12123730
|
| [29] |
Yang JN, Jin Y, Cheng SS, et al. Clinical significance for combined coagulation indexes in epithelial ovarian cancer prognosis[J]. J Ovarian Res, 2021, 14(1): 106. doi:10.1186/s13048-021-00858-1
|
| [30] |
Bishara S, Griffin M, Cargill A, et al. Pre-treatment white blood cell subtypes as prognostic indicators in ovarian cancer[J]. Eur J Obstet Gynecol Reprod Biol, 2008, 138(1): 71-5. doi:10.1016/j.ejogrb.2007.05.012
|
| [31] |
Mu J, Wu Y, Jiang C, et al. Progress in applicability of scoring systems based on nutritional and inflammatory parameters for ovarian cancer[J]. Front Nutr, 2022, 9: 809091. doi:10.3389/fnut.2022.809091
|
 ), 卓俐1, 曾敏1, 黄方俊2, 朱君1, 蔡光瑶3, 甄鑫1(
), 卓俐1, 曾敏1, 黄方俊2, 朱君1, 蔡光瑶3, 甄鑫1(