Journal of Southern Medical University ›› 2026, Vol. 46 ›› Issue (1): 231-238.doi: 10.12122/j.issn.1673-4254.2026.01.25
Haoran CHENG1,2( ), Hongbin YAN3, Ziyun YUAN4, Zehong ZHUANG1,2, Xuegang SUN5, Xueqing YAO1,2,6
), Hongbin YAN3, Ziyun YUAN4, Zehong ZHUANG1,2, Xuegang SUN5, Xueqing YAO1,2,6
Received:2025-09-02
Online:2026-01-20
Published:2026-01-16
Contact:
Xueqing YAO
E-mail:chenghaoran@gdph.org.cn
Supported by:Haoran CHENG, Hongbin YAN, Ziyun YUAN, Zehong ZHUANG, Xuegang SUN, Xueqing YAO. Research progress of large language models in tumor diagnosis: applications in textual reports and medical imaging[J]. Journal of Southern Medical University, 2026, 46(1): 231-238.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.j-smu.com/EN/10.12122/j.issn.1673-4254.2026.01.25
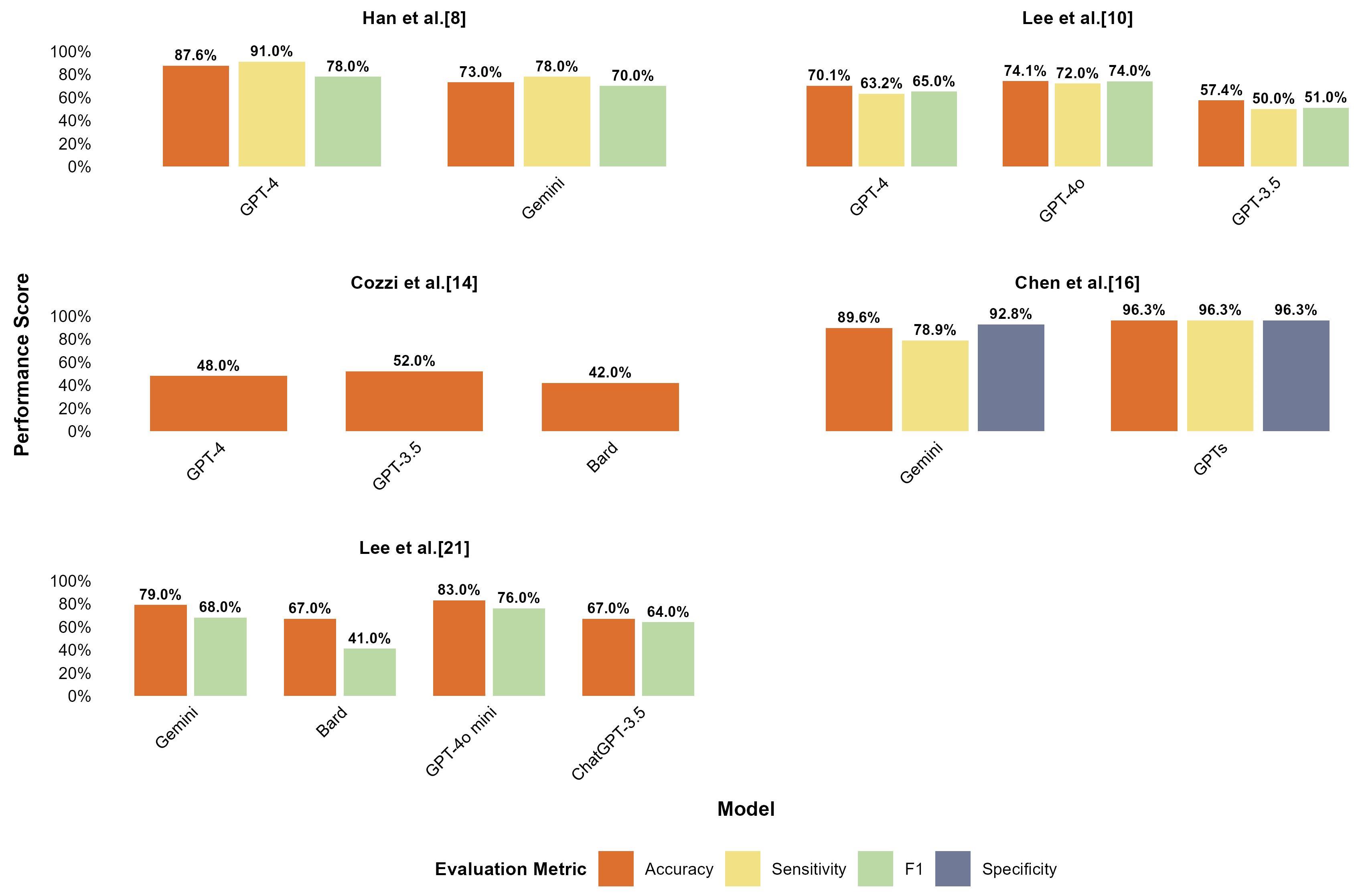
Fig.1 Comparison of performance of the mainstream large language models (LLMs) in different studies.
| Literature | LLMs | Accuracy (%) | Evaluation metrics | Prompt engineering | Fine-tuning strategy |
|---|---|---|---|---|---|
| Kim et al.[ | Orca2_13b (deductive pre-trained model) | 93.4 | F1-score: T classification: 0.889, N classification: 0.997 | Three-step prompting (clarify task, provide glossary, structured output) | Chain-of-thought, Low-rank adaptation |
| Orca2_7b (deductive pre-trained model) | 91.4 | F1-score: T classification: 0.886, N classification: 0.992 | |||
| Llama2_7b (basic open-source model) | 86.4 | F1-score: T classification: 0.750, N classification: 0.967 | |||
| Mistral_7b (basic open-source model) | 57.2 | F1-score: T classification: 0.515, N classification: 0.888 | |||
| Cho et al.[ | Deductive Mistral-7B (deductive pre-trained model) | 92.24 | F1-score: Tumor max size: 0.9939, Nodule location: 0.2939, T classification: 0.9860, N classification: 0.7845 | Three-step prompting (role assignment, clarify task, structured output) | Low-rank adaptation |
| Orca-2 (deductive pre-trained model) | 91.15 | F1-score: Tumor Max size: 0.9939, Nodule location: 0.4097, T classification: 0.9905, N classification: 0.7811 | |||
| Llama-2-70B (commercial large-parameter model) | 75.78 | F1-score: Tumor max size: 0.9788, Nodule location: 0.2027, T classification: 0.8776, N classification: 0.7271 | |||
| Llama-2-7B (basic open-source model) | 62.89 | F1-score: Tumor max size: 0.9438, Nodule location: 0.4725, T classification: 0.8567, N classification: 0.6331 | Low-rank adaptation, Deductive datasets pre-training | ||
| Mistral-7B (basic open-source model) | 19.57 | F1-score: Tumor max size: 0.9543, Nodule location: 0.0568, T classification: 0.8000, N classification: 0.5188 | |||
| Cheligeer et al.[ | GPT-2 (fine-tuned version) | 95.80 | Sensitivity: 95.3%, Specificity: 96% | None | Feed-forward neural network layer, Low-rank adaptation |
| BART | 94.40 | Sensitivity: 100%, Specificity: 92% | Text chunking, Token embedding | ||
| BioClinicalBERT | 90.10 | Sensitivity: 95.2%, Specificity: 86% | |||
| GPT-2 (base version) | 88.70 | Sensitivity: 85.7%, Specificity: 90% | |||
| GPT-2 (large version) | 88.70 | Sensitivity: 100%, Specificity: 92% |
Tab.1 Comparison of the performance of major open-source and commercial LLMs in different studies
| Literature | LLMs | Accuracy (%) | Evaluation metrics | Prompt engineering | Fine-tuning strategy |
|---|---|---|---|---|---|
| Kim et al.[ | Orca2_13b (deductive pre-trained model) | 93.4 | F1-score: T classification: 0.889, N classification: 0.997 | Three-step prompting (clarify task, provide glossary, structured output) | Chain-of-thought, Low-rank adaptation |
| Orca2_7b (deductive pre-trained model) | 91.4 | F1-score: T classification: 0.886, N classification: 0.992 | |||
| Llama2_7b (basic open-source model) | 86.4 | F1-score: T classification: 0.750, N classification: 0.967 | |||
| Mistral_7b (basic open-source model) | 57.2 | F1-score: T classification: 0.515, N classification: 0.888 | |||
| Cho et al.[ | Deductive Mistral-7B (deductive pre-trained model) | 92.24 | F1-score: Tumor max size: 0.9939, Nodule location: 0.2939, T classification: 0.9860, N classification: 0.7845 | Three-step prompting (role assignment, clarify task, structured output) | Low-rank adaptation |
| Orca-2 (deductive pre-trained model) | 91.15 | F1-score: Tumor Max size: 0.9939, Nodule location: 0.4097, T classification: 0.9905, N classification: 0.7811 | |||
| Llama-2-70B (commercial large-parameter model) | 75.78 | F1-score: Tumor max size: 0.9788, Nodule location: 0.2027, T classification: 0.8776, N classification: 0.7271 | |||
| Llama-2-7B (basic open-source model) | 62.89 | F1-score: Tumor max size: 0.9438, Nodule location: 0.4725, T classification: 0.8567, N classification: 0.6331 | Low-rank adaptation, Deductive datasets pre-training | ||
| Mistral-7B (basic open-source model) | 19.57 | F1-score: Tumor max size: 0.9543, Nodule location: 0.0568, T classification: 0.8000, N classification: 0.5188 | |||
| Cheligeer et al.[ | GPT-2 (fine-tuned version) | 95.80 | Sensitivity: 95.3%, Specificity: 96% | None | Feed-forward neural network layer, Low-rank adaptation |
| BART | 94.40 | Sensitivity: 100%, Specificity: 92% | Text chunking, Token embedding | ||
| BioClinicalBERT | 90.10 | Sensitivity: 95.2%, Specificity: 86% | |||
| GPT-2 (base version) | 88.70 | Sensitivity: 85.7%, Specificity: 90% | |||
| GPT-2 (large version) | 88.70 | Sensitivity: 100%, Specificity: 92% |
| [1] | Alan MT. Computing machinery and intelligence[J/OL]. Mind, 1950, 59(236): 433-60. doi:10.1093/mind/lix.236.433 |
| [2] | Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J]. J Mach Learn Res, 2003(3): 1137-55. |
| [3] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J/OL]. arXiv. . doi:10.65215/pc26a033 |
| [4] | Devlin J, Chang MW, Lee K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[J/OL]. arXiv. . |
| [5] | Liu Y, Han T, Ma S, et al. Summary of ChatGPT-related research and perspective towards the future of large language models[J]. Meta-Radiology, 2023, 1(2): 100017. doi:10.1016/j.metrad.2023.100017 |
| [6] | 孙 磊, 汪安安, 宋一敏, 等. 大语言模型在临床医学领域的应用、挑战和展望[J/OL]. 解放军医学院学报, 2025, 46(1): 50-60. |
| [7] | Di Palma L, Darvizeh F, Alì M, et al. Structured transformation of unstructured prostate MRI reports using large language models[J]. Tomography, 2025, 11(6): 69. |
| [8] | Han NY, Shin K, Kim MJ, et al. Enhancing oncological surveillance through large language model-assisted analysis: a comparative study of GPT-4 and gemini in evaluating oncological issues from serial abdominal CT scan reports[J]. Acad Radiol, 2025, 32(5): 2385-91. doi:10.1016/j.acra.2024.10.050 |
| [9] | Sheng LJ, Chen YD, Wei H, et al. Large language models for diagnosing focal liver lesions from CT/MRI reports: a comparative study with radiologists[J]. Liver Int, 2025, 45(6): e70115. |
| [10] | Lee JH, Min JH, Gu K, et al. Automated resectability classification of pancreatic cancer CT reports with privacy-preserving open-weight large language models: a multicenter study[J]. J Med Syst, 2025, 49(1): 118. doi:10.1007/s10916-025-02248-2 |
| [11] | Lee JE, Park KS, Kim YH, et al. Lung cancer staging using chest CT and FDG PET/CT free-text reports: comparison among three ChatGPT large language models and six human readers of varying experience[J]. AJR Am J Roentgenol, 2024, 223(6): e2431696. doi:10.2214/ajr.24.31696 |
| [12] | Li RH, Mao S, Zhu CM, et al. Enhancing pulmonary disease prediction using large language models with feature summarization and hybrid retrieval-augmented generation: multicenter metho-dological study based on radiology report[J]. J Med Internet Res, 2025, 27: e72638. |
| [13] | Fervers P, Hahnfeldt R, Kottlors J, et al. ChatGPT yields low accuracy in determining LI-RADS scores based on free-text and structured radiology reports in German language[J]. Front Radiol, 2024, 4: 1390774. doi:10.3389/fradi.2024.1390774 |
| [14] | Cozzi A, Pinker K, Hidber A, et al. BI-RADS category assignments by GPT-3.5, GPT-4, and google bard: a multilanguage study[J]. Radiology, 2024, 311(1): e232133. doi:10.1148/radiol.232133 |
| [15] | Suzuki K, Yamada H, Yamazaki H, et al. Preliminary assessment of TNM classification performance for pancreatic cancer in Japanese radiology reports using GPT-4[J]. Jpn J Radiol, 2025, 43(1): 51-5. doi:10.1007/s11604-024-01643-y |
| [16] | Chen K, Xu WG, Li XF. The potential of gemini and GPTs for structured report generation based on free-text 18F-FDG PET/CT breast cancer reports[J]. Acad Radiol, 2025, 32(2): 624-33. doi:10.1016/j.acra.2024.08.052 |
| [17] | Jiang H, Xia SJ, Yang YX, et al. Transforming free-text radiology reports into structured reports using ChatGPT: a study on thyroid ultrasonography[J]. Eur J Radiol, 2024, 175: 111458. |
| [18] | Watts E, Pournik O, Allington R, et al. Enhancing diagnostic precision: utilising a large language model to extract U scores from thyroid sonography reports[J]. Stud Health Technol Inform, 2025, 328: 56-60. |
| [19] | Mitsuyama Y, Tatekawa H, Takita H, et al. Comparative analysis of GPT-4-based ChatGPT's diagnostic performance with radiologists using real-world radiology reports of brain tumors[J]. Eur Radiol, 2025, 35(4): 1938-47. doi:10.1007/s00330-024-11281-7 |
| [20] | Gu K, Lee JH, Shin J, et al. Using GPT-4 for LI-RADS feature extraction and categorization with multilingual free-text reports[J]. Liver Int, 2024, 44(7): 1578-87. doi:10.1111/liv.15891 |
| [21] | Lee KL, Kessler DA, Caglic I, et al. Assessing the performance of ChatGPT and Bard/Gemini against radiologists for Prostate Imaging-Reporting and Data System classification based on prostate multiparametric MRI text reports[J]. Br J Radiol, 2025, 98(1167): 368-74. doi:10.1093/bjr/tqae236 |
| [22] | Singh R, Hamouda M, Chamberlin JH, et al. ChatGPT vs. Gemini: Comparative accuracy and efficiency in Lung-RADS score assignment from radiology reports[J]. Clin Imaging, 2025, 121: 110455. doi:10.1016/j.clinimag.2025.110455 |
| [23] | Hussain S, Naseem U, Ali M, et al. TECRR: a benchmark dataset of radiological reports for BI-RADS classification with machine learning, deep learning, and large language model baselines[J]. BMC Med Inform Decis Mak, 2024, 24(1): 310. doi:10.1186/s12911-024-02717-7 |
| [24] | Brown TB, Mann B, Ryder N, et al. Language models are few-shot learners[J/OL]. arXiv. . |
| [25] | Tay SB, Low GH, Wong GJE, et al. Use of natural language processing to infer sites of metastatic disease from radiology reports at scale[J]. JCO Clin Cancer Inform, 2024, 8: e2300122. doi:10.1200/cci.23.00122 |
| [26] | Wang ZX, Zhang Z, Traverso A, et al. Assessing the role of GPT-4 in thyroid ultrasound diagnosis and treatment recommendations: enhancing interpretability with a chain of thought approach[J]. Quant Imaging Med Surg, 2024, 14(2): 1602-15. doi:10.21037/qims-23-1180 |
| [27] | Liu J, Blanton T, Elazar Y, et al. OLMoTrace: Tracing language model outputs back to trillions of training tokens[J/OL]. arXiv. . doi:10.18653/v1/2025.acl-demo.18 |
| [28] | Kim S, Jang S, Kim B, et al. Automated pathologic TN classification prediction and rationale generation from lung cancer surgical pathology reports using a large language model fine-tuned with chain-of-thought: algorithm development and validation study[J]. JMIR Med Inform, 2024, 12: e67056. doi:10.2196/67056 |
| [29] | Cho H, Yoo S, Kim B, et al. Extracting lung cancer staging descriptors from pathology reports: a generative language model approach[J]. J Biomed Inform, 2024, 157: 104720. doi:10.1016/j.jbi.2024.104720 |
| [30] | Hewitt KJ, Wiest IC, Carrero ZI, et al. Large language models as a diagnostic support tool in neuropathology[J]. J Pathol Clin Res, 2024, 10(6): e70009. doi:10.1002/2056-4538.70009 |
| [31] | Cheligeer K, Wu GS, Laws A, et al. Validation of large language models for detecting pathologic complete response in breast cancer using population-based pathology reports[J]. BMC Med Inform Decis Mak, 2024, 24(1): 283. doi:10.1186/s12911-024-02677-y |
| [32] | Yang XW, Zhang Y, Jiang JY, et al. Harnessing GPT-4 for automated error detection in pathology reports: Implications for oncology diagnostics[J]. Digit Health, 2025, 11: 20552076251346703. |
| [33] | Pan YF, Tian S, Guo J, et al. Clinical feasibility of AI doctors: evaluating the replacement potential of large language models in outpatient settings for central nervous system tumors[J]. Int J Med Inform, 2025, 203: 106013. doi:10.1016/j.ijmedinf.2025.106013 |
| [34] | Liu CX, Wei MY, Qin Y, et al. Harnessing large language models for structured reporting in breast ultrasound: a comparative study of open AI (GPT-4.0) and microsoft Bing (GPT-4)[J]. Ultrasound Med Biol, 2024, 50(11): 1697-703. doi:10.1016/j.ultrasmedbio.2024.07.007 |
| [35] | Xian MF, Lan WT, Zhang Z, et al. Enhancing hepatocellular carcinoma diagnosis in non-high-risk patients: a customized ChatGPT model integrating contrast-enhanced ultrasound[J]. Radiol Med, 2025, 130(7): 1013-23. doi:10.1007/s11547-025-01994-0 |
| [36] | Horiuchi D, Tatekawa H, Shimono T, et al. Accuracy of ChatGPT generated diagnosis from patient's medical history and imaging findings in neuroradiology cases[J]. Neuroradiology, 2024, 66(1): 73-9. doi:10.1007/s00234-023-03252-4 |
| [37] | Chen LC, Zack T, Demirci A, et al. Assessing large language models for oncology data inference from radiology reports[J]. JCO Clin Cancer Inform, 2024, 8: e2400126. doi:10.1200/cci.24.00126 |
| [38] | Laukamp KR, Terzis RA, Werner JM, et al. Monitoring patients with glioblastoma by using a large language model: accurate summ-arization of radiology reports with GPT-4[J]. Radiology, 2024, 312(1): e232640. doi:10.1148/radiol.232640 |
| [39] | Cabezas E, Toro-Tobon D, Johnson T, et al. ChatGPT-4's accuracy in estimating thyroid nodule features and cancer risk from ultrasound images[J]. Endocr Pract, 2025, 31(6): 716-23. |
| [40] | Ozenbas C, Engin D, Altinok T, et al. ChatGPT-4o's performance in brain tumor diagnosis and MRI findings: a comparative analysis with radiologists[J]. Acad Radiol, 2025, 32(6): 3608-17. doi:10.1016/j.acra.2025.08.001 |
| [41] | Baker HP, Aggarwal S, Kalidoss S, et al. Diagnostic accuracy of ChatGPT-4 in orthopedic oncology: a comparative study with residents[J]. Knee, 2025, 55: 153-60. doi:10.1016/j.knee.2025.04.004 |
| [42] | Chen ZM, Chambara N, Wu CQ, et al. Assessing the feasibility of ChatGPT-4o and Claude 3-Opus in thyroid nodule classification based on ultrasound images[J]. Endocrine, 2025, 87(3): 1041-9. doi:10.1007/s12020-024-04066-x |
| [43] | Tekcan Sanli DE, Sanli AN, Yildirim D, et al. Can ChatGPT detect breast cancer on mammography [J]. J Med Screen, 2025, 32(3): 172-5. doi:10.1177/09691413251334587 |
| [44] | Wu SH, Tong WJ, Li MD, et al. Collaborative enhancement of consistency and accuracy in US diagnosis of thyroid nodules using large language models[J]. Radiology, 2024, 310(3): e232255. doi:10.1148/radiol.232255 |
| [45] | Guo LF, Zuo YT, Yisha Z, et al. Diagnostic performance of advanced large language models in cystoscopy: evidence from a retrospective study and clinical cases[J]. BMC Urol, 2025, 25(1): 64. |
| [46] | Mao YQ, Xu N, Wu YN, et al. Assessments of lung nodules by an artificial intelligence chatbot using longitudinal CT images[J]. Cell Rep Med, 2025, 6(3): 101988. doi:10.1016/j.xcrm.2025.101988 |
| [47] | Tozuka R, Johno H, Amakawa A, et al. Application of NotebookLM, a large language model with retrieval-augmented generation, for lung cancer staging[J]. Jpn J Radiol, 2025, 43(4): 706-12. |
| [48] | Valerio AG, Trufanova K, de Benedictis S, et al. From segmentation to explanation: Generating textual reports from MRI with LLMs[J]. Comput Methods Programs Biomed, 2025, 270: 108922. doi:10.1016/j.cmpb.2025.108922 |
| [49] | Ahmad Abbasi A, Farooqi AH. Integrating CT image reconstruction, segmentation, and large language models for enhanced diagnostic insight[J]. Med Biol Eng Comput, 2025. doi: 10.1007/s11517-025-03446-3 . |
| [50] | Zhu LB, Rwigema JM, Feng X, et al. Improving the precision of deep-learning-based head and neck target auto-segmentation by leveraging radiology reports using a large language model[J]. Cancers (Basel), 2025, 17(12): 1935. doi:10.3390/cancers17121935 |
| [51] | Pradhan P. Accuracy of ChatGPT 3.5, 4.0, 4o and Gemini in diagnosing oral potentially malignant lesions based on clinical case reports and image recognition[J]. Med Oral Patol Oral Cir Bucal, 2025, 30(2): e224-31. |
| [52] | Ding L, Fan L, Shen M, et al. Evaluating ChatGPT's diagnostic potential for pathology images[J]. Front Med: Lausanne, 2024, 11: 1507203. doi:10.3389/fmed.2024.1507203 |
| [53] | Vaira LA, Lechien JR, Maniaci A, et al. Diagnostic performance of ChatGPT-4o in analyzing oral mucosal lesions: a comparative study with experts[J]. Medicina, 2025, 61(8): 1379. doi:10.3390/medicina61081379 |
| [54] | Laohawetwanit T, Apornvirat S, Asaturova A, et al. Evaluation of general-purpose large language models as diagnostic support tools in cervical cytology[J]. Pathol Res Pract, 2025, 274: 156159. doi:10.1016/j.prp.2025.156159 |
| [55] | Hang H, Yang LK, Wang ZJ, et al. Comparative analysis of accuracy and completeness in standardized database generation for complex multilingual lung cancer pathological reports: large language model-based assisted diagnosis system vs. DeepSeek, GPT-3.5, and healthcare professionals with varied professional titles, with task load variation assessment among medical staff[J]. Front Med (Lausanne), 2025, 12: 1618858. doi:10.3389/fmed.2025.1618858 |
| [56] | Sng GGR, Xiang Y, Lim DYZ, et al. A multimodal large language model as an end-to-end classifier of thyroid nodule malignancy risk: usability study[J]. JMIR Form Res, 2025, 9: e70863. doi:10.2196/70863 |
| [57] | Pan C, Lu W, Chen BL, et al. Automated literature screening for hepatocellular carcinoma treatment through integration of 3 large language models: methodological study[J]. JMIR Med Inform, 2025, 13: e76252. doi:10.2196/76252 |
| [58] | Alber DA, Yang ZH, Alyakin A, et al. Medical large language models are vulnerable to data-poisoning attacks[J]. Nat Med, 2025, 31(2): 618-26. doi:10.1038/s41591-024-03445-1 |
| [59] | Korngiebel DM, Mooney SD. Considering the possibilities and pitfalls of Generative Pre-trained Transformer 3 (GPT-3) in healthcare delivery[J]. NPJ Digit Med, 2021, 4(1): 93. doi:10.1038/s41746-021-00464-x |
| [60] | Shayegani E, Mamun MAA, Fu Y, et al. Survey of vulnerabilities in large language models revealed by adversarial attacks[J/OL]. arXiv. . |
| [61] | Lenz S, Ustjanzew A, Jeray M, et al. Can open source large language models be used for tumor documentation in Germany‑An evaluation on urological doctors' notes[J]. BioData Min, 2025, 18(1): 48. doi:10.1186/s13040-025-00463-8 |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||