Journal of Southern Medical University ›› 2025, Vol. 45 ›› Issue (6): 1343-1352.doi: 10.12122/j.issn.1673-4254.2025.06.24
Yedong LIANG1( ), Xiongfeng ZHU2, Meiyan HUANG1, Wencong ZHANG1, Hanyu GUO1, Qianjin FENG1()
), Xiongfeng ZHU2, Meiyan HUANG1, Wencong ZHANG1, Hanyu GUO1, Qianjin FENG1()
Received:2025-01-07
Online:2025-06-20
Published:2025-06-27
Contact:
Qianjin FENG
E-mail:liangyedongsmu@163.com;fengqj99@smu.edu.cn
Supported by:Yedong LIANG, Xiongfeng ZHU, Meiyan HUANG, Wencong ZHANG, Hanyu GUO, Qianjin FENG. CRAKUT:integrating contrastive regional attention and clinical prior knowledge in U-transformer for radiology report generation[J]. Journal of Southern Medical University, 2025, 45(6): 1343-1352.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.j-smu.com/EN/10.12122/j.issn.1673-4254.2025.06.24
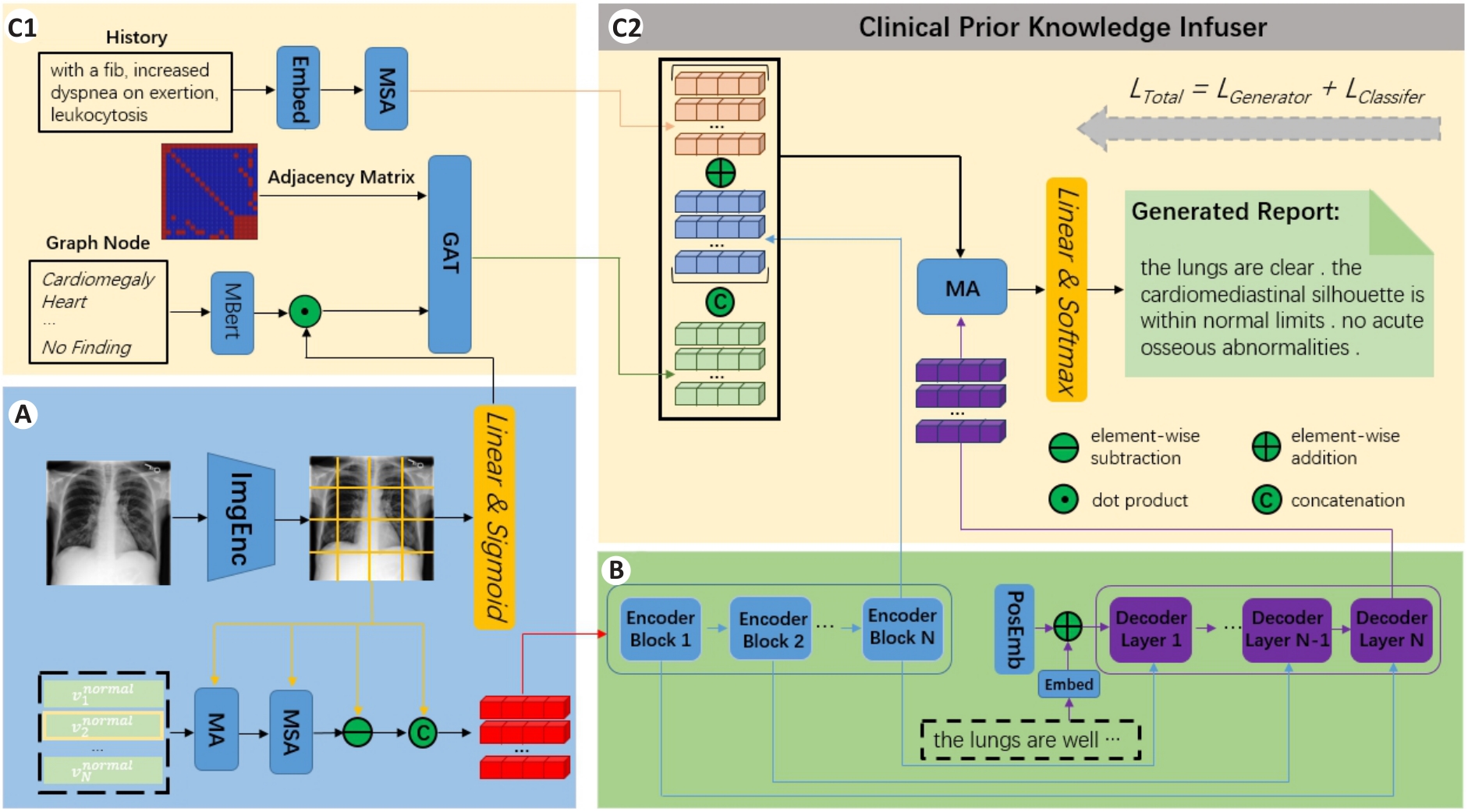
Fig.1 Overall architecture of Contrastive Regional Attention and Knowledge infused U-Transformer (CRAKUT). A: An image encoder with contrastive regional attention module; B: A Transformer that uses a U-shaped connection between the encoder and decoder; C1, C2: The knowledge infuser that fuses reports with knowledge graph and clinical history.

Fig.2 Illustration of the proposed Contrastive Regional Attention (CRA) module. The yellow line represents the flow direction of the input image, and the red box in the final result represents the region that has been enhanced due to the presence of anomalies.
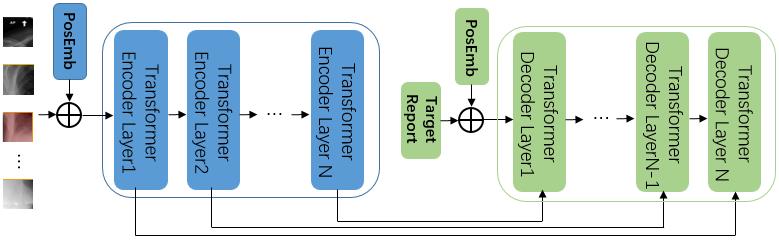
Fig.3 Connection scheme of U-shaped transformer implement by inputting the results of shallow encoding into deep decoding.
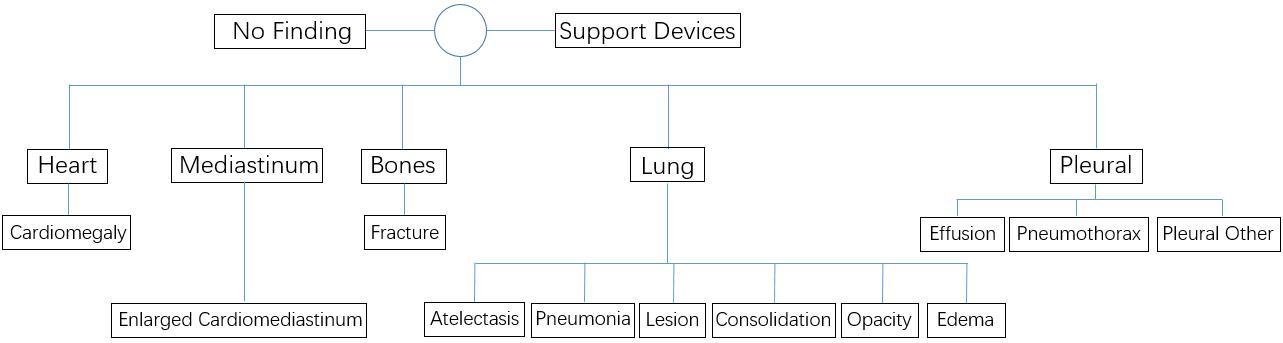
Fig.4 Efficient construction of a medical knowledge graph illustrating the relationship between symptoms and organs using ChatGPT.
| Methods | MIMIC-CXR | IU-Xray | ||||||
|---|---|---|---|---|---|---|---|---|
| BLEU-4 | ROUGE-L | METEOR | CIDEr | BLEU-4 | ROUGE-L | METEOR | CIDEr | |
| R2Gen[ | 0.103 | 0.277 | 0.142 | 0.253 | 0.165 | 0.371 | 0.187 | 0.398 |
| PPKED[ | 0.106 | 0.284 | 0.149 | 0.237 | 0.168 | 0.376 | 0.190 | 0.351 |
| MGSK[ | 0.115 | 0.284 | - | 0.203 | 0.178 | 0.381 | - | 0.382 |
| ME[ | 0.124 | 0.291 | 0.152 | 0.362 | 0.172 | 0.380 | 0.192 | 0.435 |
| DCL[ | 0.109 | 0.284 | 0.150 | 0.281 | 0.163 | 0.383 | 0.193 | 0.586 |
| KiUT[ | 0.113 | 0.285 | 0.160 | - | 0.185 | 0.409 | 0.242 | - |
| RGRG[ | 0.126 | 0.264 | 0.168 | 0.495 | - | - | - | - |
| Ours | 0.159 | 0.357 | 0.157 | 0.500 | 0.165 | 0.355 | 0.258 | 0.566 |
Tab.1 Comparison of the performance of the proposed CRAKUT model with other state-of-the-art models on the IU X-ray and MIMIC-CXR datasets
| Methods | MIMIC-CXR | IU-Xray | ||||||
|---|---|---|---|---|---|---|---|---|
| BLEU-4 | ROUGE-L | METEOR | CIDEr | BLEU-4 | ROUGE-L | METEOR | CIDEr | |
| R2Gen[ | 0.103 | 0.277 | 0.142 | 0.253 | 0.165 | 0.371 | 0.187 | 0.398 |
| PPKED[ | 0.106 | 0.284 | 0.149 | 0.237 | 0.168 | 0.376 | 0.190 | 0.351 |
| MGSK[ | 0.115 | 0.284 | - | 0.203 | 0.178 | 0.381 | - | 0.382 |
| ME[ | 0.124 | 0.291 | 0.152 | 0.362 | 0.172 | 0.380 | 0.192 | 0.435 |
| DCL[ | 0.109 | 0.284 | 0.150 | 0.281 | 0.163 | 0.383 | 0.193 | 0.586 |
| KiUT[ | 0.113 | 0.285 | 0.160 | - | 0.185 | 0.409 | 0.242 | - |
| RGRG[ | 0.126 | 0.264 | 0.168 | 0.495 | - | - | - | - |
| Ours | 0.159 | 0.357 | 0.157 | 0.500 | 0.165 | 0.355 | 0.258 | 0.566 |
| Methods | Precision | Recall | F1-score |
|---|---|---|---|
| R2Gen | 0.333 | 0.273 | 0.276 |
| MGSK | 0.458 | 0.348 | 0.371 |
| ME | 0.364 | 0.309 | 0.311 |
| DCL | 0.471 | 0.352 | 0.373 |
| KiUT | 0.371 | 0.318 | 0.321 |
| RGRG | 0.461 | 0.475 | 0.447 |
| Ours | 0.418 | 0.303 | 0.351 |
Tab.2 Comparison of clinical efficacy indicators on the MIMIC-CXR dataset
| Methods | Precision | Recall | F1-score |
|---|---|---|---|
| R2Gen | 0.333 | 0.273 | 0.276 |
| MGSK | 0.458 | 0.348 | 0.371 |
| ME | 0.364 | 0.309 | 0.311 |
| DCL | 0.471 | 0.352 | 0.373 |
| KiUT | 0.371 | 0.318 | 0.321 |
| RGRG | 0.461 | 0.475 | 0.447 |
| Ours | 0.418 | 0.303 | 0.351 |
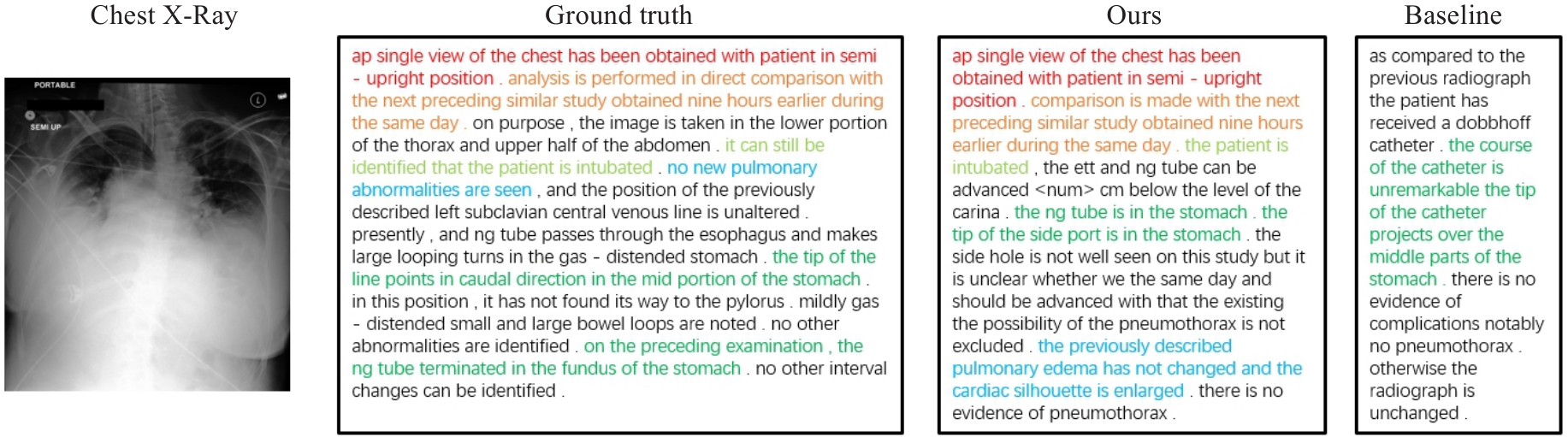
Fig.5 Report illustrations from ground truth, R2Gen[18] and the propose model. For better visualization, different colors highlight different symptoms. The richer the colors are in the report, the more clinical descriptive sentences it contains.
| 1 | Raoof S, Feigin D, Sung A, et al. Interpretation of plain chest roentgenogram[J]. Chest, 2012, 141(2): 545-58. doi:10.1378/chest.10-1302 |
| 2 | Jing BY, Xie PT, Xing E. On the automatic generation of medical imaging reports[EB/OL]. 2017. . doi:10.18653/v1/p18-1240 |
| 3 | Vinyals O, Toshev A, Bengio S, et al. Show and tell: a neural image caption generator[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015: 3156-64. doi:10.1109/cvpr.2015.7298935 |
| 4 | Liu FL, Yin CC, Wu X, et al. Contrastive attention for automatic chest X-ray report generation[EB/OL]. 2021. . doi:10.18653/v1/2021.findings-acl.23 |
| 5 | Johnson AEW, Pollard TJ, Greenbaum NR, et al. MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs[EB/OL]. 2019. . doi:10.1038/s41597-019-0322-0 |
| 6 | Demner-Fushman D, Kohli MD, Rosenman MB, et al. Preparing a collection of radiology examinations for distribution and retrieval[J]. J Am Med Inform Assoc, 2016, 23(2): 304-10. doi:10.1093/jamia/ocv080 |
| 7 | Brown T, Mann B, Ryder N, et al. Language models are few-shot learners [J]. Adv Neural Information Processing Systems, 2020, 33:1877-901. |
| 8 | Huang ZZ, Zhang XF, Zhang ST. KiUT: knowledge-injected U-transformer for radiology report generation[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023: 19809-18. doi:10.1109/cvpr52729.2023.01897 |
| 9 | Nguyen HTN, Nie D, Badamdorj T, et al. Automated generation of accurate & fluent medical X-ray reports[EB/OL]. 2021. . doi:10.18653/v1/2021.emnlp-main.288 |
| 10 | Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 4700-8. doi:10.1109/cvpr.2017.243 |
| 11 | Huang L, Wang WM, Chen J, et al. Attention on attention for image captioning[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019: 4634-43. doi:10.1109/iccv.2019.00473 |
| 12 | Vaswani A, Shazeer N, Parmar N, et al. Polosukhin, "Attention is all you need"[J]. Adv Neural Information Processing Systems, 2017,30: 1305. |
| 13 | Tran A, Mathews A, Xie LX. Transform and tell: entity-aware news image captioning[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020: 13035-45. doi:10.1109/cvpr42600.2020.01305 |
| 14 | Pan YW, Yao T, Li YH, et al. X-linear attention networks for image captioning[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020: 10971-80. doi:10.1109/cvpr42600.2020.01098 |
| 15 | Cornia M, Stefanini M, Baraldi L, et al. Meshed-memory transformer for image captioning[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020: 10578-87. doi:10.1109/cvpr42600.2020.01059 |
| 16 | Nguyen VQ, Suganuma M, Okatani T. GRIT: faster and better image captioning transformer using dual visual features[M]//Cham: Springer Nature Switzerland, 2022: 167-84. doi:10.1007/978-3-031-20059-5_10 |
| 17 | Xu K, Ba J, Kiros R,et al. Show, attend and tell: Neural image caption generation with visual attention[J]. Computer Science, 2015, (2): 2048-57. doi:10.1109/cvpr.2015.7298935 |
| 18 | Jing BY, Wang ZY, Xing E. Show, describe and conclude: on exploiting the structure information of chest X-ray reports[EB/OL]. 2020. . doi:10.18653/v1/p19-1657 |
| 19 | Liu G, Hsu H, McDermott M, et al. Clinically accurate chest x-ray report generation[J]. PMLR, 2019, 106: 249-69. |
| 20 | Chen ZH, Shen YL, Song Y, et al. Cross-modal memory networks for radiology report generation[EB/OL]. 2022. . doi:10.18653/v1/2021.acl-long.459 |
| 21 | Chen ZH, Song Y, Chang TH, et al. Generating radiology reports via memory-driven transformer[EB/OL]. 2020. . doi:10.18653/v1/2020.emnlp-main.112 |
| 22 | Li M, Liu R, Wang F, et al. Auxiliary signal-guided knowledge encoder-decoder for medical report generation[J]. World Wide Web, 2023, 26(1): 253-70. doi:10.1007/s11280-022-01013-6 |
| 23 | Wang J, Bhalerao A, He YL. Cross-modal prototype driven network for radiology report generation[M]//Computer Vision. Springer Nature Switzerland, 2022: 563-79. doi:10.1007/978-3-031-19833-5_33 |
| 24 | Liu FL, Wu X, Ge S, et al. Exploring and distilling posterior and prior knowledge for radiology report generation[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021: 13753-62. doi:10.1109/cvpr46437.2021.01354 |
| 25 | Zhang Y, Wang X, Xu Z, et al. When radiology report generation meets knowledge graph [C]// Proceedings of the AAAI Conference on Artificial Intelligence, 2020: 12910-7. doi:10.1609/aaai.v34i07.6989 |
| 26 | Yin CC, Qian BY, Wei JS, et al. Automatic generation of medical imaging diagnostic report with hierarchical recurrent neural network[C]//2019 IEEE International Conference on Data Mining (ICDM), 2019: 728-37. doi:10.1109/icdm.2019.00083 |
| 27 | You D, Liu FL, Ge S, et al. AlignTransformer: hierarchical alignment of visual regions and disease tags for medical report generation[C]//Medical Image Computing and Computer Assisted Intervention, 2021: 72-82. doi:10.1007/978-3-030-87199-4_7 |
| 28 | Wang ZY, Tang MK, Wang L, et al. A medical semantic-assisted transformer for radiographic report generation[C]//Medical Image Computing and Computer Assisted Intervention, 2022: 655-64. doi:10.1007/978-3-031-16437-8_63 |
| 29 | Yang S, Wu X, Ge S, et al. Knowledge matters: Chest radiology report generation with general and specific knowledge[J]. Med Image Anal, 2022, 80: 102510. doi:10.1016/j.media.2022.102510 |
| 30 | Wang ZY, Liu LQ, Wang L, et al. METransformer: radiology report generation by transformer with multiple learnable expert tokens[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023: 11558-67. doi:10.1109/cvpr52729.2023.01112 |
| 31 | Li M, Lin B, Chen Z, et al. Dynamic graph enhanced contrastive learning for chest x-ray report generation[C]//2023 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023: 3334-43. doi:10.1109/cvpr52729.2023.00325 |
| 32 | Tanida T, Müller P, Kaissis G, et al.Interactive and explainable region-guided radiology report generation[C]//IEEE/CVF Con-ference on Computer Vision and Pattern Recognition, 2023: 7433-42. doi:10.1109/cvpr52729.2023.00718 |
| No related articles found! |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||